728x90
반응형
이전 글 : 2022.08.09 - [데이터/빅데이터분석기사] - [빅데이터분석기사 필기] 2과목 - 빅데이터 탐색 (3/3) (어려움)
지난 글에서는 빅데이터 탐색을 위해 통계기법을 배웠다. 이번에는 새로운 과목으로 넘어가 빅데이터 모델링에 대해 다루고자 한다. 이번 글은 데이터에듀에서 발행한 '빅데이터 분석기사 필기' 교재 제2권의 8~32페이지에 해당하는 부분을 공부한 내용이다.
※ 출처가 있는 이미지를 클릭하면 원 사이트로 접속된다.

Index
1장 분석모형 설계
1절 분석모형 구축
1. 데이터 모델 구축 기법
- 통계 분석 : 전형적 데이터 모델 구축 기법으로 회귀분석, 로지스틱 회귀분석, 판별분석, 주성분분석이 있음.
- 회귀분석 : 종속변수에 대한 독립변수의 선형 함수관계로부터 새로운 값에 대해 종속변수의 값을 예측. 특정 예측변인이 결과변인에 미치는 인과성을 밝히는 데도 사용 가능.
- 로지스틱 회귀분석 : 설명변수가 주어졌을 때, 목표변수가 특정 그룹에 속할 확률이 로지스틱 함수 형태를 따르는 것을 활용해 개별 관측값이 어느 집단에 분류될지 예측.
- 판별분석 : 종속변인이 둘 혹은 그 이상의 그룹으로 이루어졌을 때, 복수의 독립변인으로 집단 관측값을 판별 또는 예측.
- 주성분분석 : 여러 변수가 있을 때, 상관관계가 높은 변수의 선형결합으로 만들어진 주성분이라는 새로운 변수를 만들어 변수를 요약 및 축소.
- 데이터 마이닝 : 데이터를 다양한 관점에서 분석하여 숨은 패턴과 상관성을 통계적 기법으로 식별해 가치 부여.
- 분류 (로지스틱 회귀, 의사결정 나무, SVM, K-NN 등), 예측 (회귀, 장바구니, 시계열 분석, K-NN 등), 연관 (연관성, 순차패턴 분석), 군집화 (군집분석, K-means 클러스터링, 기대최대화) 를 위해 활용.
- 머신러닝 : 데이터 마이닝 혹은 기타 학습 알고리즘으로 학습한 지식을 추출하고 이를 기반으로 비슷한 미래 사건의 결과를 예측하는 컴퓨터 프로그램. 데이터 마이닝과 유사하지만 데이터 모델의 매개 변수를 기계가 자동으로 학습한다는 것에서 차이가 있음.
- 1) 지도학습 : 입력 데이터와 원하는 출력값을 제공하며 기계를 훈련시키는 방법.
- 예측하고자 하는 반응변수를 이용해 새로운 데이터의 목적변수를 추정 혹은 분류. 주로 예측과 분류 모델에 활용.
- 2) 비지도학습 (자율 학습) : 데이터에 라벨이 붙어 있지 않은 상태로 학습 데이터 없이 입력 데이터만으로 학습하는 방식.
- 사전 정보가 없는 상태에서 현상을 이해 or 내재된 특징 도출에 활용. 군집화, 차원축소, 연관성 분석에 주로 쓰임.
- 3) 강화 학습 : 주어진 이렵값에 대한 출력값의 정답이 주어지지 않은 상황에서 일련의 결과에 대한 보상이 제공되고, 시스템은 선택 가능한 행동 중 보상을 최대화하는 선택지를 고르며 학습 진행. 경험과 시행착오를 거쳐 얻어진 데이터를 토대로 알고리즘이 모델을 개선해나가는 방법.

- 비정형 데이터 분석 : 빅데이터에서 취급하는 데이터는 정형 데이터 (스프레드시트, RDB 데이터 등), 반정형 데이터 (데이터 형식과 구조가 변경될 수 있고, 데이터 구조 정보를 데이터와 함께 제공 / JSON 등), 비정형 데이터로 분류
- 텍스트 마이닝 : 비정형 텍스트에서 정보를 추출 및 발견하는 것. 문서 분류, 군집, 정보 추출을 위한 자연어 처리 등의 방법 활용.
- 오피니언 마이닝 : 사안, 인물, 이벤트에 대한 사람들의 의견, 감정, 태도 등을 분석하는 것.
- 소셜 네트워크 분석
2. 분석모형 선정
- 선정 기준 : 명확한 목적, 종속변수의 존재 파악, 종속변수의 종류 파악
- 데이터 활용 목적에 따른 모델
- 종속변수 유무, 유형에 따라 데이터 분석 모형 선택
3. 분석모형 정의
- 선택 분석기법을 적용해 모형 정의를 위해서 데이터셋을 나눔.
- 올바른 모형 정의를 위해 데이터의 양과 품질이 중요.
4. 분석모형 구축 절차
- 순서 : 데이터 수집 및 처리 - 분석 알고리즘 수행 - 분석결과 평가 및 모형 선정
- 1) 분석 데이터 수집 및 처리
- (1) 분석 데이터 마트 구성 : 기존 사례 분석 및 최대의 데이터를 선택.
- (2) 분석 데이터 현황 분석 : 데이터 탐색 및 충실도, 이상치 등 파악.
- 2) 분석 알고리즘 수행
- (1) 분석 알고리즘 선정 : 목적, 데이터 유형, 볼륨에 맞는 알고리즘 선택.
- (2) 분석 알고리즘 수행 : 데이터셋 준비, 파라미터 설정 및 조정, 분석 결과 기록.
- 3) 분석 결과 평가 및 모델 선정
- 최종 모델 선정 시, 다양한 이해관계자가 참여. 실질적 활용 가능성 검토.
2절 분석환경 구축
1. 분석도구 선정
- MS의 엑셀, 구글의 스프레드시트
- R (R 스튜디오) : 객체 지향 언어 S를 기반으로 90년대 개발되어 GNU 프로젝트로 편입된 1997년 사용처 급상승. 오픈소스.
- Python (아나콘다, 쥬피터)
- SAS : 통계 전문가들이 주로 활용.
- SPSS : 사회과학의 데이터 분석용. GUI 방식.
- 아파치 머하웃 하이브 등
2. 데이터 분할
- 데이터 분할 : 과적합과 일반화를 위해 분석 데이터셋을 모델 개발을 위한 훈련 데이터와 모델의 검증력 평가를 위한 평가 데이터로 나누는 것.
- 훈련 데이터셋 : 가장 큼. 일반적으로 50%
- 평가 데이터셋 : 모형 성능 평가. 20%
- 검증 데이터셋 : 구축된 모형의 과대추정 or 과소추정을 미세 조정하기 위해 활용. 30% 할당.
- 데이터 분할 비율 : 양성 혹은 음성 클래스가 훈련과 평가 데이터셋에 몰리지 않도록 해야 함.
- 데이터 양이 불충분 or 입력변수에 대한 설명이 부족하다면?
- 1) 홀드아웃 : 주어진 데이터를 무작위로 두 개의 데이터로 구분하여 사용하는 것.
- 2) 교차검증 Cross Validation
- 데이터를 k개의 하위 그룹으로 나누어 k-1개의 집단을 훈련용, 나머지를 검증용으로 지정.
- k번 반복 측정한 결과 : 테스트로 얻은 평균제곱오차 MSE 값의 평균으로 최종값.
- k-fold cross validation : 이미지 참조
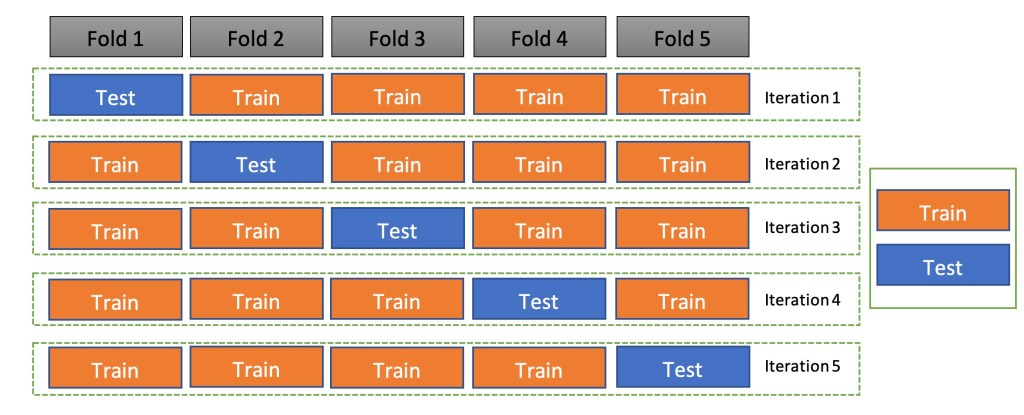
- 데이터 분할 절차 : 훈련 데이터를 활용한 분석모형 모델링 - 평가 데이터로 성능평가 - 최적 분석모형 선정.
♧ 예상문제 오답 정리
- Q-러닝 : 강화학습 알고리즘.
- Demand Forecasts - 정형 / Competitor Pricing, RFID - 반정형
- SOM (Self Organizing Maps) : 군집화 기법
- 분석 데이터 현황 분석 : 데이터 충실도, 이상치, 분포도, 오류율 고려
- 도메인 지식 - 파라미터 조정의 관계
- 평가척도
- 지도학습 (분류형) : 분류 정확도, 평균 오차율, 오류 재현율
- 비지도학습 (설명형) : 집도 소속률, 데이터 밀도 및 군집도
- 기타 (텍스트 마이닝) : 텍스트 매칭률, 문서 분류율
- 챔피온 모델 : 최종 선정 모델
- D3.js : 시각화 도구
- 결합 관련 - 파이썬은 접착제 언어
- 맵리듀스 MapReduce : 분산 환경에서의 병렬 데이터 처리 기법.
- 머하웃은 하둡 에코시스템에서 데이터 마이닝 기능 수행. 실시간 SQL 질의는 임팔라, 타조가 처리.
728x90
반응형
'Cerificate > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사 필기] 3과목 - 빅데이터 모델링 (3/5) (0) | 2022.08.14 |
|---|---|
| [빅데이터분석기사 필기] 3과목 - 빅데이터 모델링 (2/5) (0) | 2022.08.11 |
| [빅데이터분석기사 필기] 2과목 - 빅데이터 탐색 (3/3) (어려움) (0) | 2022.08.09 |
| [빅데이터분석기사 필기] 2과목 - 빅데이터 탐색 (2/3) (0) | 2022.08.07 |
| [빅데이터 분석기사 필기] 2과목 - 빅데이터 탐색 (1/3) (0) | 2022.08.05 |



