728x90
반응형
- 이전 글 : 2022.08.05 - [데이터/빅데이터분석기사] - [빅데이터 분석기사 필기] 2과목 - 빅데이터 탐색 (1/3)
- 참고 글 : 2022.08.02 - [데이터/데이터 과학을 위한 통계] - [Practical Statistics for Data Scientists] 1 - 탐색적 데이터 분석 (EDA)
지난 글에서는 데이터 전처리 방법을 학습했다. 이번에는 탐색적 데이터 분석 (EDA)를 공부할 것이고, 데이터에듀에서 발행한 '빅데이터 분석기사 필기' 교재의 244~274페이지에 해당하는 내용이다.
※ 출처가 있는 이미지를 클릭하면 원 사이트로 접속된다.

Index
2장 데이터 탐색
1) 데이터 탐색 기초
(1) 데이터 탐색 개요
- 탐색적 데이터 분석 : 특이점이나 의미 있는 사실을 도출해 분석의 최종 목적을 달성하는 과정. 데이터의 구조적 관계를 파악하기 위한 방법의 통칭 (by Jonh Tukey)
- 탐색적 자료분석 ↔ 확증적 자료 분석 : EDA로 데이터를 깊게 이해한 후 보다 정교한 모형을 개발
- EDA의 4가지 주제
- 저항성 강조 : 저항성 - 훼손된 데이터가 있을 때 영향을 덜 받는 것.
- 잔차 Residual의 해석 : 잔차 - 개별 관측값이 주요 경향으로 얼마나 떨어졌는지 나타내는 지표. 이상치.
- 데이터의 재표현 : 해석에 도움이 되도록 로데이터의 척도를 변환하는 것. (ex. 로그 변환, 제곱근 변환 등)
- 데이터의 현시성 presentation : 데이터 시각화
(2) 기초통계량 추출 및 이해
- 기술통계 descriptive statistic : 데이터를 의미있는 정보로 체계화, 요약, 표현하는 방법. 요약통계량의 개발 및 산출도 포함.
- 기초통계량 (기술통계량) : 자료의 분포는 중심경향도, 산포도, 비대칭도로 나타나고, 각 특성별로 요약통계량을 산출한 것.
- 기초통계량의 추출 : 엑셀, R, SAS, Python, SPSS 등
- 중심경향도 : 자료 분포의 중심을 찾는 것. 평균, 중앙값, 최빈값.
- 중앙값 : 극단치에 영향을 받지 않으나 수리적 방법으로 산출되지 않음.

- 산포도
- 범위 : 자료의 분포가 대칭인 경우에 적합
- 분산 : 퍼져있는 정도의 평균을 의미. 자유도 개념에 의거해 n-1로 나눠줌.
- 자유도 degree of freedom : 통계적 추정을 할 때, 표본 중 모집단에 대해 정보를 주는 독립적 자료의 수를 뜻함.
- 표준편차 : 분산의 양의 제곱근. 종 모양일 때, 평균을 중심으로 정규분포.
- 사분범위 IQR
- 평균의 표준오차 SEM : 표본평균의 표준편차. 모평균과 표본평균이 얼마나 차이나는지 나타내는 통계량. n이 커질수록 작아지는 경향.
- 변동계수 CV : 변수 X의 표준편차를 산술평균으로 나눈 값. 측정 단위가 다른 자료를 비교할 때 활용됨.
- 비대칭도 asymmetry
- 왜도 skewness와 첨도 kurtosis 모두 정규분포와 비교해 설명. 정규분포는 첨도, 왜도가 전부 0
- 왜도 : 비대칭의 방향을 보여줌. 비대칭이 커질수록 왜도의 절대값 증가.
- 오른쪽으로 긴 꼬리 : 왜도 (m3) > 0
- 첨도 : 뾰족한 정도에 대한 통계량.
- 첨도가 0이면, 표준정규분포보다 더 뾰족하고 긴 꼬리를 가짐.
(3) 시각적 데이터 탐색
- 막대그래프 & 원그래프
- 막대그래프 : 범주형 변수의 값에 대한 도수를 표현. 자료 양이 적을 때 적합. 계급 간 비교가 목적.
- 원그래프 : 도수표 or 상대도수표 표현. 범주형 변수의 백분율에 대한 상대적 차이 비교.
- 도수분포표 & 히스토그램
- 도수분포표 : 연속형 자료를 일정 구간으로 나누고, 그 구간에 속한 개수를 표로 나타낸 것.
- 히스토그램: 도수분포표의 구간별 관측도수를 기둥으로 표현한 것.
- 막대그래프와 달리 히스토그램은 연속형 자료를 쓰므로 사이에 공백이 없음.
- 줄기 잎 그림
- 수치형 데이터 활용.
- 히스토그램과 비슷하지만 최솟값, 최댓값, 자료 분포에 대한 정보 파악 가능. (정보 손실 없음)
- 상자그림 Boxplot : 최솟값, 최댓값, 사분위수 활용. 줄기 잎 그림과 주로 같이 사용됨.
- 도수다각형 (도수분포다각형)
- 연속형 자료를 일정 크기의 계급으로 묶었을 때, 각 계급의 중간점에서 도수를 표시하고, 그 점을 선으로 이은 그래프.
- 히스토그램과 유사하고, 꺾은선 그래프라고도 함.
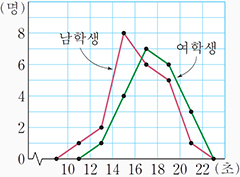
- 선그래프 : 연속형 변수에 해당하는 x축의 변화에 따른 y축의 변화를 선으로 나타낸 것. x축이 시간이면, 시계열 그래프라고도 한다.
- 산점도 : 두 변수의 변화를 나타내는 2차원 도표. 자료가 적을 때는 막대그래프나 표가 더 효과적.
(4) 상관관계 분석
- 인과관계 : 상관관계 중에서도 원인과 결과의 시간적 선후가 명확히 파악된 것
- 통계기법 : 산점도, 공분산, 상관계수
- 공분산 분석
- 공분산 : 두 변수의 공통된 분포를 나타내는 분산. 두 개의 변수값을 갖는 관측치들이 각 변수의 평균으로부터 얼마나 떨어져있는지 나타냄.
- 공분산이 0보다 작으면 음의 선형관계로, 서로 반대로 움직임. (공분산이 0이면 독립, 변수 간 선형관계 없음)
- 공분산은 두 변수 변화량의 곱으로 이루어져 다른 단위를 비교할 때 차이가 커질 수 있음.
- 따라서 표준화된 공분산 (공분산을 각각의 변수의 표준편차로 나눈 것)으로 보완 ☞ 피어슨 상관계수
- 상관계수 분석 (피어슨, 스피어만!)
- 피어슨 상관계수
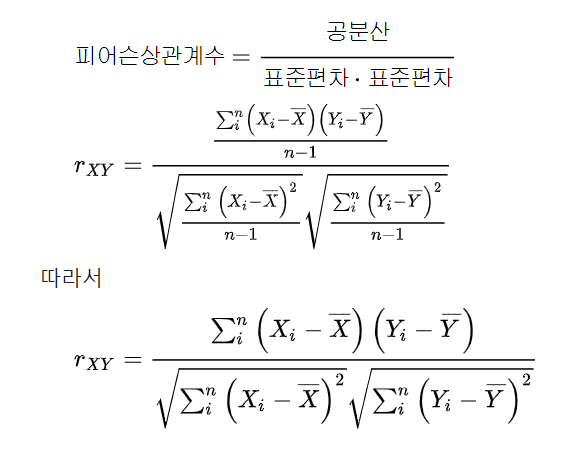
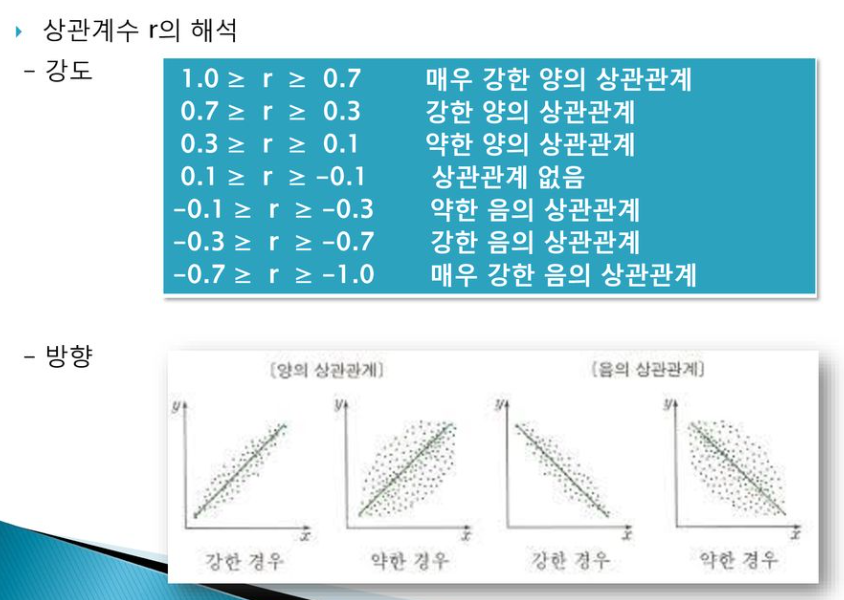
- 스피어만의 서열상관계수, 켄달의 타우
- 서얼척도 변수의 상관관계. 켄달의 타우가 보다 엄격해 계산이 용이한 전자가 많이 쓰임.
- 예시 - 기업의 매출액 순위
- 상관관계 범위 동일
- 상관계수 유의성 검정
- 상관계수를 사용하기 위해 통계적으로 유의한지 검정해야만 한다.
- 1. 가설설정 : 귀무가설과 대립가설 설정
- 귀무가설 : 선형관계 (상관관계)가 없다. ↔ 대립가설 : 선형관계가 있다.
- 2. 검정통계량 : t통계량 활용. 자유도는 n-2인 t분포.
- 3. 유의성 검정 : t-test로 검정. 유의수준 0.05보다 크면 기각.
2) 고급 데이터 탐색
(1) 시공간 데이터 탐색
- 시간 데이터 탐색은 시간의 흐름에 따른 패턴 변화를 살펴보는 것.
- 주기에 따라 반복되는 패턴 혹은 지속적으로 바뀌는 패턴을 구분하는 것이 핵심.
- 통계적 분석기법 (시계열 분석)과 시각화 도구(구글 스프레드시트 - 모션차트) 로 탐색.
- 공간 데이터는 일반적으로 위치정보를 포함한 형태로 존재.
- Arc GIS, X-Ray Map, Power Map 등 사용.
(2) 다변량 데이터 탐색
- 다변량 데이터 : 범주형. 여러 범주형 척도를 지닌 변수 데이터.
- 다변량 시각화 기법
- 피벗 테이블 : 대규모 데이터의 구조, 요약, 표시
- 모자이크 플롯 : 각 사각형의 넓이가 해당 카테고리의 데이터 수
- 레이더 차트 (스파이더 차트) : 명목변수의 수준에 따른 정량적 변수의 값을 시각적으로 표현한 것. 항목 간 비율과 경향 등을 파악하기 용이함.
- 이외에도 평행좌표 그래프, 체르노프 얼굴, 스몰 멀티플즈, 선버스트 차트, 트리맵 등 존재.
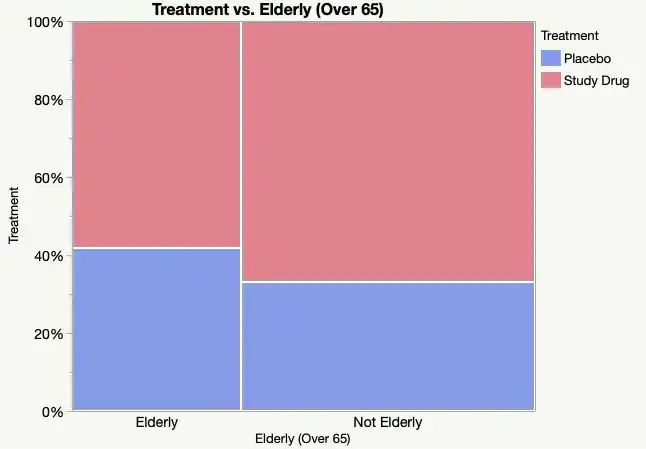
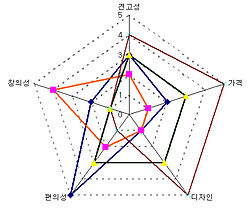
(3) 비정형 데이터 탐색
- 텍스트, 이미지, 영상, 음성, GPS 등. 빅데이터의 주관심사.
- 텍스트 데이터 : 텍스트 마이닝으로 대규모 텍스트를 추출하고 단어 빈도 분포를 살펴본다.
- 웹 데이터
- 데이터 수집 방법 - 웹 크롤링
- 스크래핑은 크롤링과 다름. 스크래핑은 코드까지 가져오는 것인데 반해 크롤링은 콘텐츠를 데이터화하는 것.
- 분석 방법 - 웹 마이닝 (정보 필터링, 경쟁사 특허 및 기술 감시, 로그 마이닝 등에 활용됨)
♧ 예상문제 오답 정리
- 측정치에 5를 더하면 평균은 5 증가, 표준편차는 일정.
- 분산 공식 :


- p-백분위수 : 전체 n개의 데이터를 크기대로 정렬하고, 관측값의 개수 n에 p (percent)를 곱한 위치에 해당하는 수.
- 파레토 그림 : 명목형 자료에서 중요한 소수를 찾는데 유용.

- 히스토그램에서 표본이 적으면 빈도가 동일해져 데이터 분포를 잘 표현하지 못함.
- 데이터 값이 동일하게 증가하면 평균도 같이 증가해 상관계수는 변하지 않음.
- 공간 데이터 탐색 도구
- X-Ray Map : 코로플레스맵 등을 생성해 실제 지역의 데이터 관계를 찾아볼 수 있음.
- Power Map : 엑셀에서 무료로 제공하는 시각화 도구. 모션차트 결합 가능.
- 선버스트 차트 : 이미지 참고
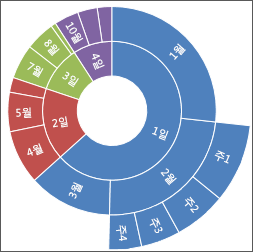
- 다변량 시각화
- 평행좌표 그래프 : 측정값 여러개 일 때 사용. 단일 그룹일 경우에 평행 좌표계 사용.
- 스몰 멀티플즈 : 다수의 변수를 하나의 차트에 표현하지 않고 영역을 구분해 표현. 라인, 막대차트, 산점도 활용 가능.
- 웹 크롤링
- Beautiful Soup, lxml, curl 라이브러리로 html 파싱.
- scarpy, nutch, crawler4j는 프레임워크로 크롤링의 아키텍처 위에 확장 가능한 기반 코드 제공.
728x90
반응형
'Cerificate > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사 필기] 3과목 - 빅데이터 모델링 (1/5) (0) | 2022.08.10 |
|---|---|
| [빅데이터분석기사 필기] 2과목 - 빅데이터 탐색 (3/3) (어려움) (0) | 2022.08.09 |
| [빅데이터 분석기사 필기] 2과목 - 빅데이터 탐색 (1/3) (0) | 2022.08.05 |
| [빅데이터 분석기사 필기] 1과목 - 빅데이터 분석 기획 (3/3) (0) | 2022.08.04 |
| [빅데이터 분석기사 필기] 1과목 - 빅데이터 분석 기획 (2/3) (0) | 2022.08.03 |



