
메타코드M의 '파이썬 입문 데이터분석 프로젝트 만들기' 강의에 관한 마지막 글이다. 첫번째로 파이썬 문법과 데이터 전처리, 두번째로 데이터 시각화를 다루었다. 이번 글에서는 EDA와 지표 정의를 학습할 것이다.
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr
※ 첫번째 글: 2024.02.08 - [Python] - [데이터 분석] 메타코드M '파이썬 입문 데이터분석 프로젝트 만들기' 강의 후기 (1/3)
※ 두번째 글: 2024.02.08 - [Python] - [데이터 분석] 메타코드M '파이썬 입문 데이터분석 프로젝트 만들기' 강의 후기 (2/3)
Index
파이썬 데이터 분석 프로젝트 #3
각 지표에 대해 배운 다음, 프로젝트 (EDA에서 광고 최적화까지)의 코드를 정리하고자 한다.
Attribution
고객의 구매나 전환에 기여한 마케팅 접점의 영향력을 평가하는 방법이다.
- First Click Attribution: 첫 클릭에 공헌도 집중.
- Last Click Attribution: 마지막 클릭에 공헌도 집중.
- Multi-Touch Attribution: 모든 고객 여정에 동일한 공헌도 배분.
질문
Q: 본 강의에서는 Cross Join으로 두 데이터프레임을 병합하여 모든 경우의 수를 산출한다. 그러나 이 경우, 데이터프레임이 굉장히 커질 수 있는 우려가 있는데 어트리뷰션을 구하기 위한 다른 접근 방식이 있는가?
A: 좋은 질문. 따라서 1일치 데이터만을 처리하여 결과값만을 저장하여 사용하는 형태로 업무 진행. 이를 데이터마트 작업이라 하고, 데이터분석가, 데이터엔지니어, 마케팅팀의 협업이 요구됨.
2024.04.09 추가
Conversion Window
전환 과정 시작 후 구매/전환까지 소요되는 기간. 완전성과 적시성을 고려해야 한다.
EDA에서 광고 최적화까지
1. 데이터 불러오기
5개의 csv파일 로드 후 시간 계산을 위해 datetime으로 type을 변경한다.
2. 데이터 전처리
필요한 데이터프레임을 병합하고 파생변수를 만든다.
# 각 그룹별로 'value' 열의 최대값을 갖는 행의 인덱스 찾기
idx = df.groupby('group')['value'].idxmax()
# 최대값을 갖는 행 선택
max_rows = df.loc[idx]idxmin()으로 특정 열에서 최솟값을 갖는 인덱스를 찾는 것도 가능하다.
본 프로젝트에서는 purchase와 visit 데이터프레임을 cross merge하여 모든 경우의 수를 고려했고, 조건에 부합하는 데이터를 거르며 last click attribution으로 데이터를 살펴보고자 했다.
order_mg['realized_revenue'] = np.where(order_mg.pay_date.isna(), 0, order_mg.total_revenue)
df_od = order_mgnp.where은 엑셀의 if 구문과 유사하다. 조건을 부여하고 이에 해당하는 true값과 false값을 적어주면 된다.
3. 데이터 분석
# 캠페인 효율성
fig = px.scatter(df[df.campaign != 'organic'],
x = 'cpc',
y = 'roas',
size = 'realized_revenue',
color = 'source')
fig.add_hrect(y0 = 0.6, y1 = 1, fillcolor = 'red', opacity = 0.35)
fig.show()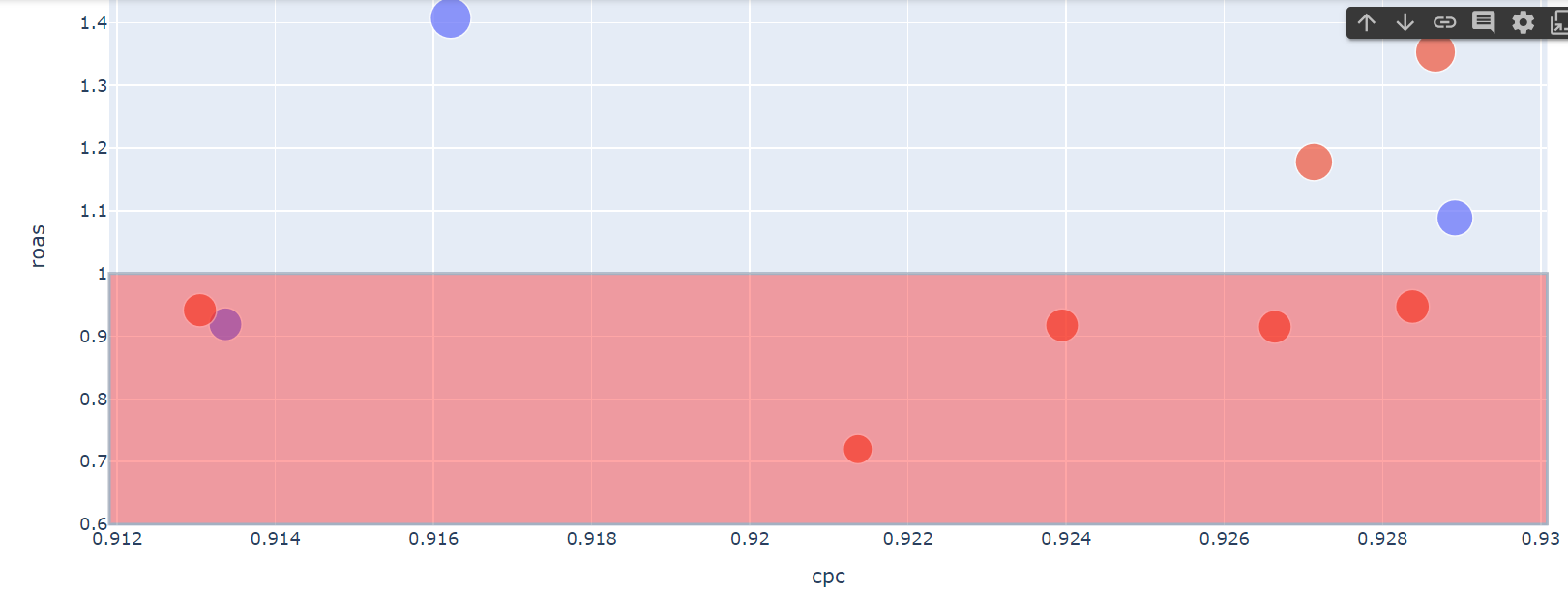
산점도와 span이 적용된 그래프이다. organic, 즉 광고가 아닌 검색 유입이 된 경우는 제외하고 분석했다.
fig = px.histogram(
order_filter,
x = 'td_day',
opacity = .35)
fig.add_vrect( x0 = -0.5, x1 = p_50, fillcolor = 'red', opacity = 0.25)
fig.add_annotation(x = p_50, text = f'{p_50}일 이내 완료되는 결제는 전체의 50%')
fig.add_vrect( x0 = -0.5, x1 = p_95, fillcolor = 'green', opacity = 0.25)
fig.add_annotation(x = p_95, text = f'{p_95}일 이내 완료되는 결제는 전체의 95%')
fig.show()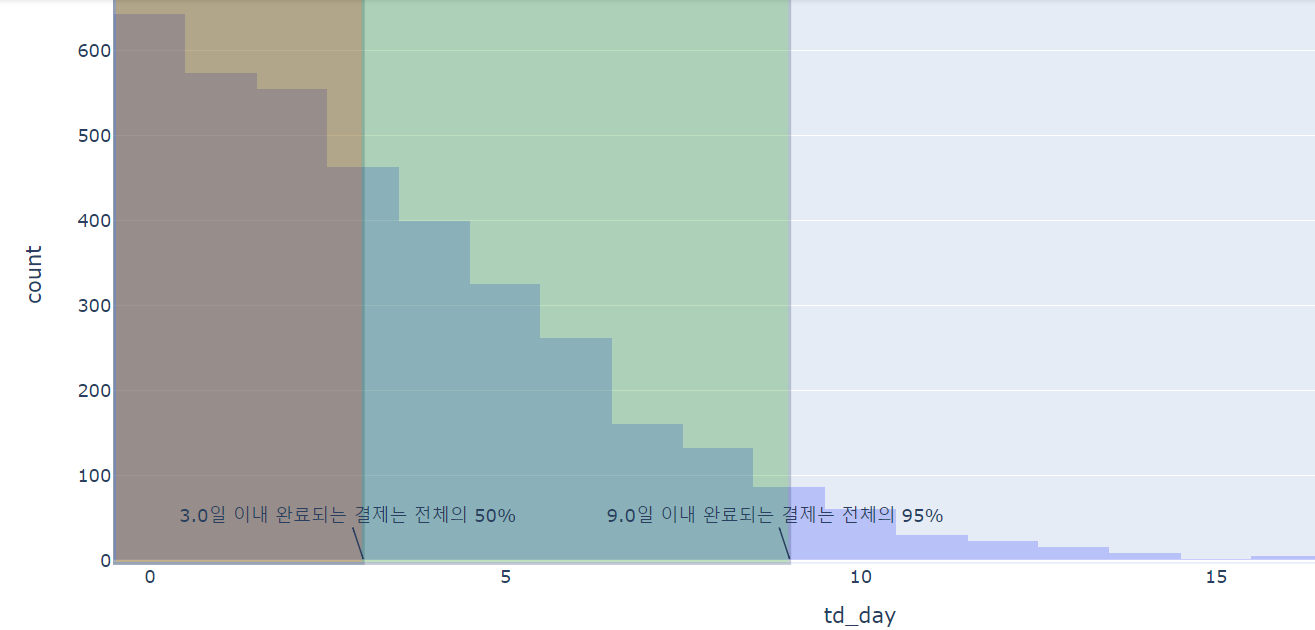
3일 이내 완료되는 결제는 전체의 절반이지만 9일 이내 완료되는 결제는 전체의 95%이므로 어느 시점을 통계의 기준으로 삼을 지 적시성과 완전성을 고려해 판단해야 한다.

매출에 따른 제품별 상관관계를 분석했더니 6번과 9번 제품에서 양의 상관관계, 1번과 17번 제품에서 음의 상관관계가 발견되었다. 상관도는 seaborn의 heatmap을 사용했다.
이외에 카테고리별 매출 트렌드, 고객분석을 시도했다. groupby.agg()를 써서 동시에 여러 통계치를 뽑아낼 수 있다.
order_mg.groupby(by = 'user_id').agg(
total_spending = ('total_revenue', 'sum'),
order_cnt = ('order_id', 'count'),
dist_prod_cnt = ('product_id', 'nunique'),
dist_cate_cnt = ('category', 'nunique')
).reset_index().describe()지금까지 데이터로 인사이트를 도출하는 과정을 알아봤다. 메타코드의 강의에서 사용된 자료는 인터넷 거래 사이트의 고객 여정과 광고의 유효성에 대한 것이었고 이를 토대로 여러 관점에서 분석하고자 했다.
실무에서 어떻게 데이터를 분석하는지 접할 수 있어 흥미로웠지만 한편으로 다양한 데이터를 만져보며 숙련도를 올려야겠다는 생각도 들었다. 포트폴리오로 바로 활용하기는 부족하다는 느낌이 있으나 코드 활용이나 분석 과정은 다른 케이스에서도 요긴하게 쓸 수 있을 듯하다.
즐겁고 행복한 명절 보내시길...!
- 24.04.09 질문 추가
'Python' 카테고리의 다른 글
| [데이터 분석] 메타코드M '파이썬 입문 데이터분석 프로젝트 만들기' 강의 후기 (2/3) (0) | 2024.02.08 |
|---|---|
| [데이터 분석] 메타코드M '파이썬 입문 데이터분석 프로젝트 만들기' 강의 후기 (1/3) (2) | 2024.02.08 |

