
메타코드M의 '파이썬 입문 데이터분석 프로젝트 만들기' 강의에 대한 두번째 글이다. 이전 포스트에서는 파이썬 기초 문법과 데이터 전처리를 학습했다. 이번에는 데이터 시각화에 대해 공부할 것이다.
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr
※ 이전글: 2024.02.08 - [Python] - [데이터 분석] 메타코드M '파이썬 입문 데이터분석 프로젝트 만들기' 강의 후기 (1/3)
Index
파이썬 데이터 분석 프로젝트 #2
주로 matplotlib나 seaborn 라이브러리를 사용해 시각화를 해왔는데 plotly.express라는 새로운 라이브러리를 import하여 여러 기능을 확인할 수 있어 참신했다.
데이터 시각화 챕터의 모든 코드를 다루지 않고 주요 코드를 공부하면서 제품 포트폴리오를 분석하는 프로젝트의 코드 중 생소한 부분을 정리할 것이다.
선그래프
facet_row 혹은 facet_col을 파라미터를 지정해 서브플롯을 구현하면 여러 개의 그래프를 그릴 수 있다. 아래 그래프는 facet_row를 지정하여 나타냈다.
import plotly.express as px
# 선 그래프 생성
line_fig = px.line(df_agg2
, x="pickup_date" # X축에 표시할 컬럼
, y="total" # Y축에 표시할 컬럼
, color="payment" # 각 선의 색상을 구분하기 위한 컬럼
, facet_row="color" # 서브플롯을 구분하기 위한 컬럼 (세로로 나누기)
# facet_row="col_5"를 사용하면 가로로 나눌 수 있음
#, title="title_name" # 그래프의 제목
)
# line_fig.update_layout(xaxis_title="x_title_name", yaxis_title="y_title_name")
# 선 그래프 표시
line_fig.show()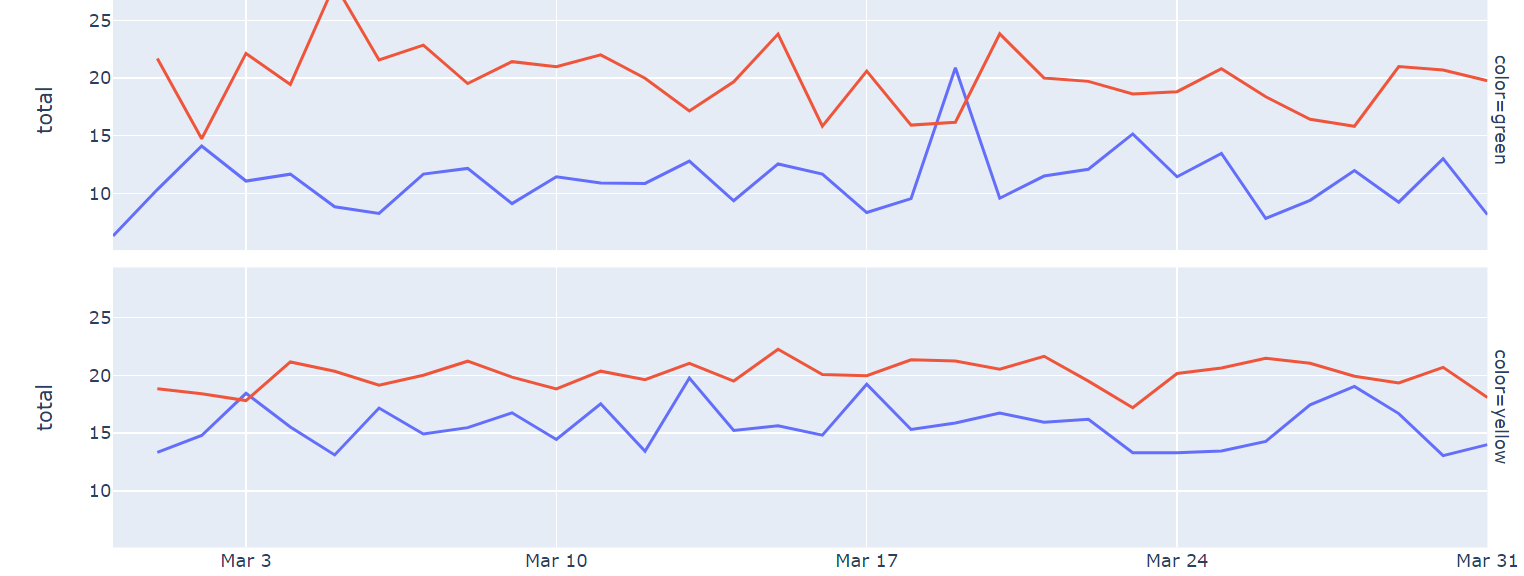
히스토그램
span을 설정해 필요한 부분을 강조할 수 있다.
avg = filtered_iris.sepal_length.mean()
std = filtered_iris.sepal_length.std()
import plotly.express as px
# 히스토그램 생성
fig = px.histogram(
filtered_iris, # 사용할 데이터셋
x='sepal_length', # x축에 사용할 열 이름
height = 500,
width = 700,
title= f'{iris_name} histogram'
)
# 세로선 추가
fig.add_vline(
x=avg, # 세로선의 x축 위치
)
# 주석 추가
fig.add_annotation(
x=avg , # 주석의 x축 위치
y=30, # 주석의 y축 위치
text="{:.2f}".format(avg) # 표시할 텍스트
)
# 세로 스팬 추가
fig.add_vrect(
x0= avg-std, # 스팬의 시작 x축 위치
x1= avg+std, # 스팬의 종료 x축 위치
fillcolor="red", # 스팬의 색상
opacity=.2, # 스팬의 불투명도
)
# 히스토그램 표시
fig.show()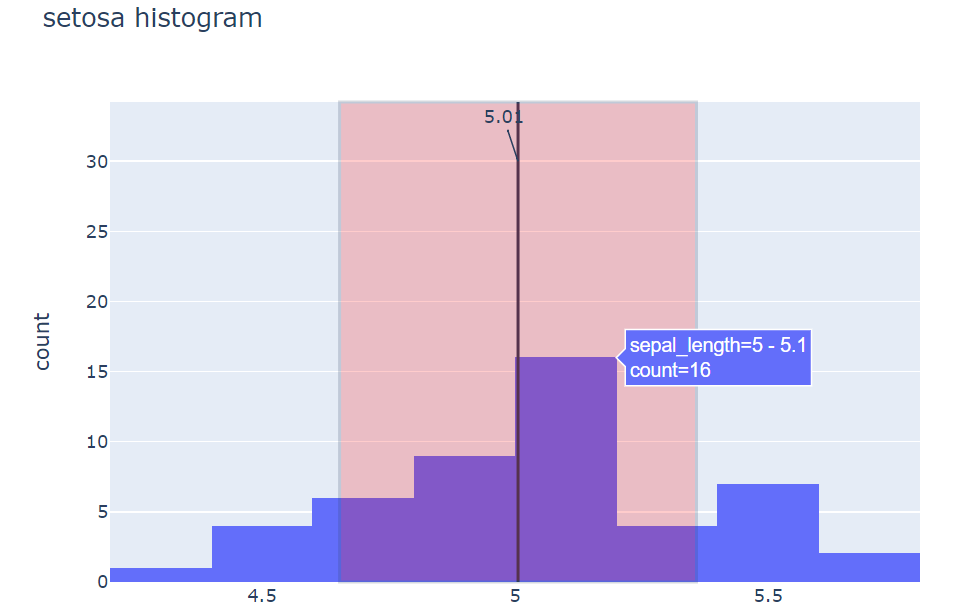
제품 포트폴리오 분석
1. 데이터프레임 탐색
구글 드라이브를 mount하여 pd.read_csv로 데이터프레임을 불러온 후 product_id, category, price라는 3가지 기준으로 그룹핑했다. 이전 강의와 마찬가지로 net profit ratio, total net profit과 같은 파생변수를 추가했다.
2. 데이터 시각화
fig = px.scatter(
df_agg,
x = 'total_revenue',
y = 'net_profit_ratio',
height = 500,
width = 700,
title = '제품 포트폴리오 분석',
hover_name = 'product_id',
size = 'total_net_profit',
color = 'discount_ratio'
)
fig.show()산점도를 그리는 기능을 사용했다. 파라미터로 x, y축으로 사용할 컬럼을 정해주고 합계 총 이윤 (total_net_profit)에 따라 점의 크기가 달라지도록 설정했다. hover_name은 마우스 커서를 가져다 대면 해당 점의 product_id를 표시하도록 설정하는 파라미터이다.
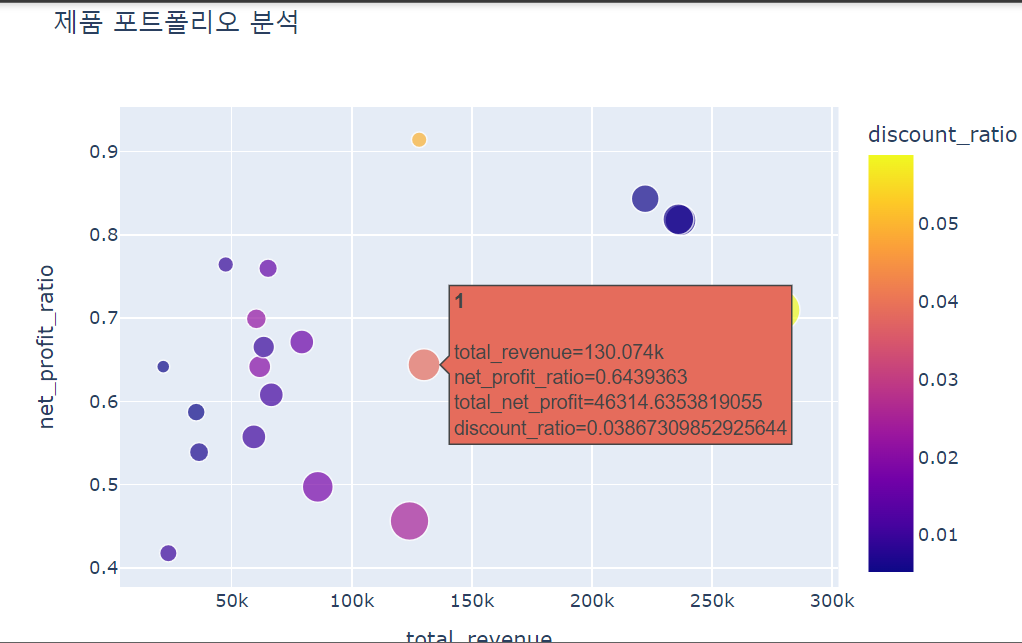
위 산점도로 총매출과 이익률, 그리고 할인율을 모두 파악할 수 있다. 예를 들어, 4개의 사분면으로 나누어 매출은 낮지만 이익률이 좋은 제품이 무엇인지, 또 그 제품이 할인폭이 크지 않았음에도 매출이 잘 나왔다면 이유가 무엇인지 추가적인 분석을 시도하는 것도 가능하다.
다음 글에서는 탐색적 데이터 분석 (EDA)과 지표 정의에 대해 다룰 예정이다.
'Python' 카테고리의 다른 글
| [데이터 분석] 메타코드M '파이썬 입문 데이터분석 프로젝트 만들기' 강의 후기 (3/3) (1) | 2024.02.08 |
|---|---|
| [데이터 분석] 메타코드M '파이썬 입문 데이터분석 프로젝트 만들기' 강의 후기 (1/3) (2) | 2024.02.08 |

