728x90
반응형

지난 시간에 이어 메타코드M의 '통계 기초의 모든 것' 강의를 정리해보도록 하겠다. 이전글은 아래의 링크를 참조바란다.
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr
Index
통계 기초의 모든 것
1. 이산확률분포
- 베르누이 시행: 사상이 2개인 시행 (ex.성공 or 실패)
- 이항확률분포: 베르누이 시행을 반복하여 특정 횟수의 성공 or 실패가 나올 확률.
- n: 시행횟수, p: 성공 확률
- 기댓값: np
- 분산: np(1-p)
- 포아송분포: 단위시간, 단위공간 내 어떤 사건이 발생하는 횟수를 나타낸 확률분포

2. 연속확률분포
- Unifrom Distribution: 가장 간단한 분포
- f(x) = 1/(b-a)
- 기댓값: (a+b)/2
- 정규분포 (가우스분포): 가장 널리 사용
- 표준정규분포: 평균 0, 표준편차가 1인 정규분포. Z분포라고 함.
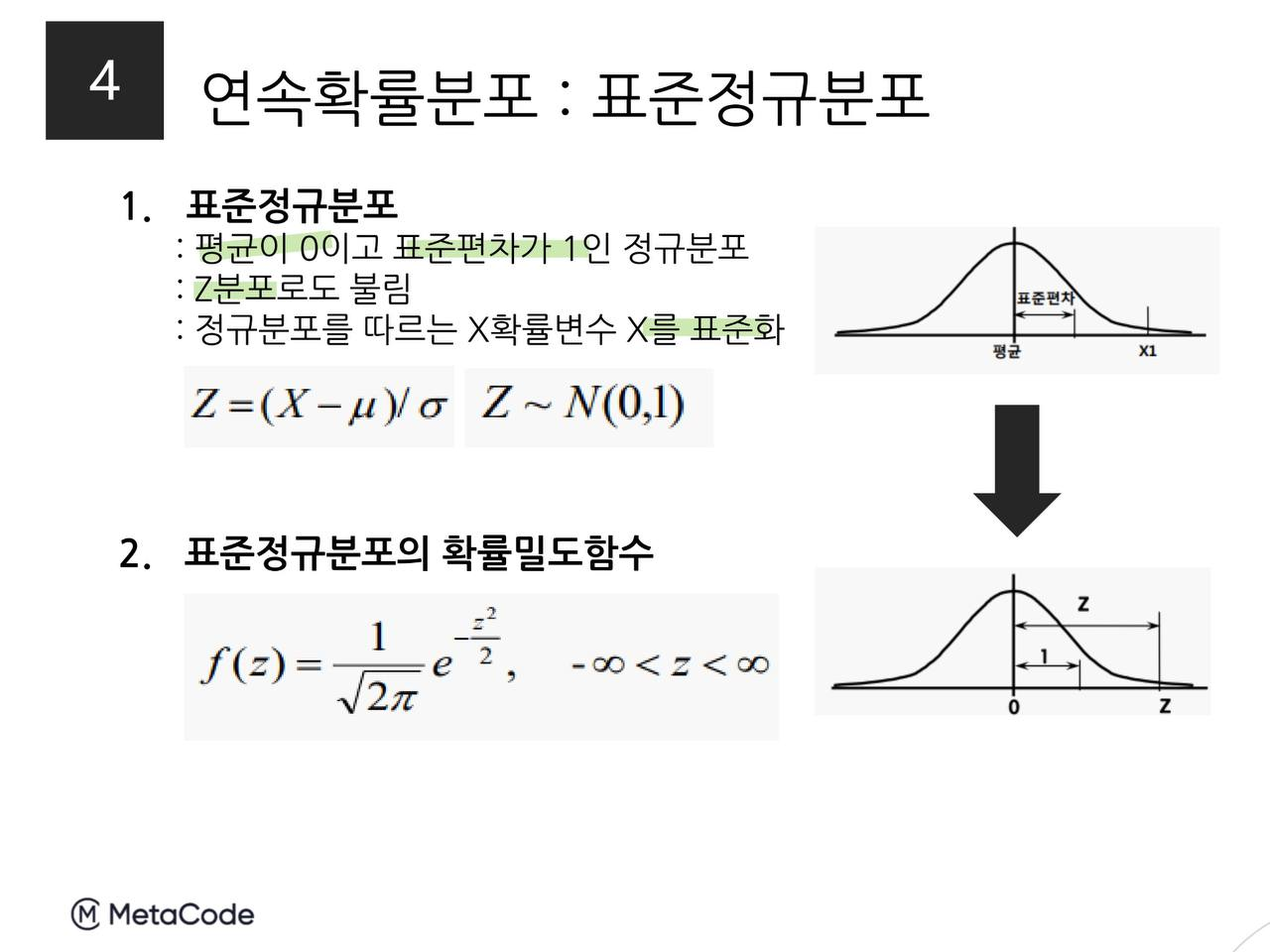
※ 표준화 by 뤼튼
통계학에서 표준화(standardization)는 데이터를 특정한 기준에 따라 변환하는 과정을 의미합니다. 특히, 표준화는 각 데이터가 평균으로부터 얼마나 떨어져 있는지를 나타내는 값으로 변환하는 것을 말합니다.
표준화된 값은 원래 값에서 평균을 뺀 다음 표준 편차로 나누어 계산하며, 이렇게 변환된 값을 Z-점수(Z-score)라고도 합니다.
수식으로 표현하면 다음과 같습니다:
Z = (X - µ) / σ
여기서 X는 원래의 데이터 값을, µ(뮤)는 데이터의 평균 값을, σ(시그마)는 데이터의 표준 편차를 의미합니다.
표준화를 통해 변환된 데이터의 평균은 0, 표준 편차는 1이 됩니다.
- 표본분포: 모집단에서 일정한 크기로 도출가능한 표본을 모두 뽑았을 때, 모든 표본의 통계량의 확률분포
- 중심극한정리

- 카이제곱분포: 표본분산과 관련. 확률변수 Z가 표준정규분포를 따르고 독립일 때, 이 제곱합은 자유도 k인 카이제곱분포를 따름. (표본분산을 알고 모분산 추정 시 사용.)
- t분포: X가 정규분포일 때 (모집단의 표준편차를 모르는 경우 ▷ 표본표준편차 사용.)
- F-분포: 두 정규모집단의 분산을 비교할 때 사용.
3. 통계적 추정
- 기준: 불편성, 유효성, 일치성, 충분성
- 점추정
- 표준오차: 통계량의 표준편차. 표본크기가 클수록 작음.
- 구간추정: 표본에서 구할 수 있는 정보를 토대로 모수가 속할 것으로 기대되는 범위 (신뢰구간)을 택하는 과정
- 신뢰구간: 모수를 포함할 것으로 추정한 구간
- 신뢰수준: 신뢰구간이 모수를 포함할 확률. 1-a (a: 오차율)
- 모분산을 아는 경우와 모르는 경우로 나누어 생각. 모르는 경우는 t통계량 사용.

※ Z통계량 by 뤼튼
Z통계량(또는 Z-점수, Z-score)은 표준화 과정을 거친 결과로, 개별 데이터 값이 평균에서 얼마나 떨어져 있는지를 나타내는 값입니다.
Z통계량은 다음과 같은 수식으로 계산됩니다:
Z = (X - µ) / σ
여기서, X는 원본 데이터 값, µ(뮤)는 데이터 세트의 평균, σ(시그마)는 데이터 세트의 표준 편차를 의미합니다.
Z통계량이 양수인 경우, 해당 데이터 값은 평균보다 크다는 것을 나타냅니다. 반대로, Z통계량이 음수인 경우, 해당 데이터 값은 평균보다 작다는 것을 나타냅니다. Z통계량의 절대값은 데이터 값이 평균에서 얼마나 떨어져 있는지를 나타내며, 이는 '표준 편차 단위'로 표현됩니다.
예를 들어, 특정 학생의 표준화된 시험 점수(Z-점수)가 1.5라면, 해당 학생의 점수는 평균 점수보다 1.5 표준 편차만큼 높다는 것을 의미합니다.
이처럼 Z통계량은 데이터를 비교하거나 분석할 때 중요한 도구로 사용됩니다.
※ t통계량 by 뤼튼
t통계량은 표본의 평균이 모집단의 평균과 유의미하게 다른지를 검증하기 위한 도구입니다. 이는 작은 표본 크기(small sample size)에서 주로 사용되며, 표본의 평균이 모집단의 평균과 얼마나 떨어져 있는지를 측정하는데 사용됩니다.
t통계량은 다음과 같은 수식으로 계산됩니다:
t = (X̄ - µ) / (s / √n)
여기서, X̄는 표본 평균, µ(뮤)는 모집단의 평균, s는 표본의 표준편차, n은 표본의 크기를 나타냅니다.
t통계량은 이론적으로 t분포를 따르며, t분포는 표준정규분포와 비슷한 형태를 가지지만, 꼬리 부분이 약간 더 두껍고 길다는 특징이 있습니다. 이는 t분포가 작은 표본 크기에서도 안정적인 추정을 가능하게 하기 때문입니다.
따라서 t통계량은 특히 표본 크기가 작을 때, 즉 표준편차의 추정치가 불안정할 때 유용하게 사용됩니다.
4. 통계검정
- 유의수준 (a): 기간/채택 판단 기준. 1종 오류를 범할 확률의 최대 허용한계.
- 가설의 종류
- 귀무가설 (H0): 일반적 사실. ex) 효과가 없다, 차이가 없다.
- 대립가설 (H1): 입증하고자 하는 가설.
- 가설설정의 오류

- 유의확률 (p-value): 귀무가설을 기각할 수 있는 최소의 유의수준. 귀무가설이 사실일 확률. (a > p-value, 귀무가설 기각)
- 임계값: 기각역과 채택역을 나누는 경계값. 관측값이 기각역에 속하면 귀무가설 기각.
- 모평균 검정
- 정규모집단인 경우: 모집단을 알면 Z통계량, 모르면 t통계량 (자유도 n-1)
- 표본 크기가 큰 임의의 모집단: 모분산을 알건, 모르건 모두 Z통계량.
통계에 대한 기초적인 지식을 다뤄봤다. 아직 체화는 덜 됐으나 어렴풋한 흐름과 개념은 파악할 수 있었다. 예제도 있으니 교재를 보면서 반복적으로 학습하면 도움이 될 것이다.
728x90
반응형
'Statistics' 카테고리의 다른 글
| [통계] 메타코드M '통계 기초의 모든 것' 공부 후기 (1/2) (0) | 2024.01.22 |
|---|
