
빅데이터 분석기사 취득 후 데이터 공부를 하지 않아 안타깝게도 대부분의 지식이 유실되었다. 이 비극적인 상황에서 벗어나고자 '메타코드M'의 힘을 빌리기로 결심했다. '메타코드M'에 올라온 많은 유익한 강의들을 보며 데이터에 대한 기초를 다시 쌓고 나아가 업무 역량을 키우고자 한다. 데이터 분석의 기초는 통계라고 할 수 있는만큼 먼저 기본적인 통계 이론을 짚어볼 것이다.
Index
'메타코드M'이란?
먼저 '메타코드M'이 무엇인지 소개하고 본론으로 들어가도록 하겠다. '메타코드M'은 데이터, 코딩 등의 강의를 제공하는 플랫폼이자 관련 산업에 발을 내디딜 수 있도록 취업 정보, 업계 지식 등을 공유하는 커뮤니티이기도 하다. 필자는 유튜브에서 처음 접했는데 유익한 영상들이 많이 나와 조금씩 보다가 강의를 보고 공부를 하는 과정으로 넘어 왔다. 참고로 '메타코드M'의 영상은 괄호 안의 링크를 통해 확인할 수 있다. (Youtube)
통계 기초의 모든 것
이 강의는 고려대 출신의 데이터 분석가인 곽호빈님이 진행하였다. 아래 사이트에서 수강할 수 있고 7개의 강의로 구성된 약 5시간까지의 강의다. 이번 글에서는 3강 확률과 확률변수의 내용까지 다룰 것이다.
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr
1. 데이터의 종류

1강의 핵심은 데이터의 종류를 이해하는 것이다. 데이터의 속성에 따라 이를 처리하는 모델링 방법이 달라지기 때문에 올바른 분석을 위해 데이터의 종류를 확실히 판별하여야 한다. 아, 강의에 들어가기 앞서 자료를 꼭 받아두도록 하자.

- 범주형 자료
- 명목형 자료
- 순서형 자료
- 양적 자료
- 이산형 자료
- 연속형 자료
위와 같이 나눌 수 있다. 여기서 길이와 시간을 왜 셀 수 없다고 설명하는지 이해가 잘 되지 않을 수 있다. 길이와 시간 등의 데이터는 무한히 쪼갤 수 있기 때문이다. 길이는 센티, 밀리, 나노... 등으로 세분화가 가능하고 시간도 밀리 세컨드, 나노 세컨드 등으로 끊임없이 잘게 자를 수 있다. 따라서 연속형, 즉 무한히 계속된다고 볼 수 있고, 무한하기에 셀 수 없다고 설명할 수 있는 것이다.
2. 통계량
통계량은 표본에 대한 수치적 요약이다. 영어로는 statistic이라고 한다. 표본을 통해 모집단을 파악하는 것이 통계의 핵심인데 통계량은 표본을 묘사하는 척도라고 볼 수 있기에 통계량을 잘 살펴보는 것이 기본 중 기본이라 할 수 있다. 이 강의는 통계량을 중심, 산포, 형태, 상관의 측면에서 정리한다.

중심에서는 최빈값, 중앙값, 평균이 나오는데 이중 가장 생소했던 개념은 기하평균이었다. 기하평균은 이전 시점 대비 변화율을 나타내는 개념으로 5년간 평균 물가상승률 등을 나타낼 때 사용할 수 있다.
산포는 얼마나 분산되어 있는지 살펴보는 지표라 할 수 있다. 편차 제곱을 자료 수로 나눈 분산으로 확인할 수 있고 제곱근을 씌워 scale을 조정한 표준편차로도 산포를 알 수 있다.

형태를 나타내는 통계량으로는 왜도와 첨도가 있다. 분포가 비대칭적으로 그려질 때, 최빈값과 중앙값, 그리고 평균이 어떻게 위치되는지 물어보는 문제는 데이터를 다루는 시험에서 자주 출제된다.
마지막으로 상관을 표현하는 통계량이 있는데 그중에서도 피어슨 상관계수는 아래의 공식으로 도출할 수 있다. 이것은 공분산을 두 변수의 표준편차의 곱으로 나눈 값이고 -1~1 사이의 값을 갖는다.
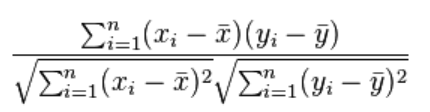
3. 확률과 확률변수
사건은 사상이라고도 하는데 표본 공간의 부분집합이다. 이중 배반사상은 두 집합 사이에 교집합이 없는 것을 의미한다.

조건부확률은 특정 사건이 일어날 것을 전제로 다른 사건이 일어날 확률을 뜻한다. 데이터 분석 시, 데이터를 추가함에 따라 예측값이 어떻게 변하는지도 조건부 확률이 적용된 사례라고 할 수 있겠다. 예제로 A 속성의 고객이 B 제품을 구입할 확률 등이 있다.
독립과 종속은 어떤 사건의 발생이 타 사건의 발생 확률에 영향을 주는지에 따라 갈린다. 현실에서는 서로 얽히고설킨 사건들이 많기에 종속사건이 대부분이다.

베이즈 정리는 조건부확률에 기반하여 사전확률과 사후확률의 관계을 나타낸 것이다. 간단히 말하자면, 사전확률을 짐작하고, 데이터에 의거해 관측될 확률을 도출한 다음 최종적인 확률을 이끌어낸다고 할 수 있다.

확률변수는 표본공간에서 정의된 실수 함수로 확률분포는 확률변수의 값과 각 확률을 대응시켜 시각화한 것이다. 확률변수는 이산확률변수와 연속확률변수로 나눌 수 있다. 이산확률변수는 확률변수에 따라 각 확률을 대응할 수 있지만 연속확률변수는 구간의 면적을 계산하여 확률을 구해야 한다.

기댓값은 확률변수가 지니는 모든 값의 평균인데 확률변수의 유형에 따라 구하는 공식이 다르다. 또 다음과 같은 성질을 가진다.

통계 공부를 마치고 빅데이터분석기사 자격 취득을 노리는 독자들을 위해 링크를 남겨 놓도록 하겠다.
그럼 다음 글에서는 확률분포와 통계검정에 대한 내용을 정리하며 '통계기초의 모든 것' 강의를 마무리짓고자 한다.
'Statistics' 카테고리의 다른 글
| [통계] 메타코드M '통계 기초의 모든 것' 공부 후기 (2/2) (0) | 2024.02.04 |
|---|
