
이번 메타코드M 강의에서는 크롤링으로 '예매 가능한 기차표 찾기 프로젝트'를 해보고자 한다. 대략적인 흐름은 코레일 사이트에서 특정 일자를 지정해서 데이터를 가져오고, 해당일의 가장 이른 시간에 출발하는 티켓의 URL을 가져오는 것이다.
※ 이전글: 2024.03.27 - [Python/Web Crawling] - [데이터 수집] 메타코드M '웹 크롤링 기초 강의' #2 - 뉴스 크롤링 자동화 프로젝트
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr
Index
3강. 예매 가능한 기차표 찾기 프로젝트
사이트 규정 및 페이지 구조 파악 & 표 데이터 크롤링
코레일의 열차 데이터를 활용한다. 다만 크롤링을 진행하기 앞서, robots.txt를 주소의 뒤에 넣고 크롤링을 금지하는지 미리 살펴봐야 한다. 크롤링을 허용한다고 해도 서버에 부하를 많이 주지 않도록 필요한 데이터만 가져와야 한다.

Selenium으로 가져온 데이터를 soup이라는 변수에 담고 표 데이터가 있는 tbody의 데이터를 가져온다. 코레일 사이트에서 표의 구조를 보려면 표의 가장자리 부분을 잘 클릭해야 하는데 이게 좀 귀찮다.

td 파트를 찾아 get_text로 텍스트를 찾는데 공백이 많기에 strip=True를 설정하여 깔끔하게 정리한다. 행이 들어갈 빈 리스트, 열이 들어갈 빈 리스트를 만들고 반복문으로 td에 해당하는 데이터를 넣어주는 것이다. 그런데 텍스트는 잘 긁어왔으나 버튼 모양의 이미지로 된 데이터는 불러오는 데 실패했다.
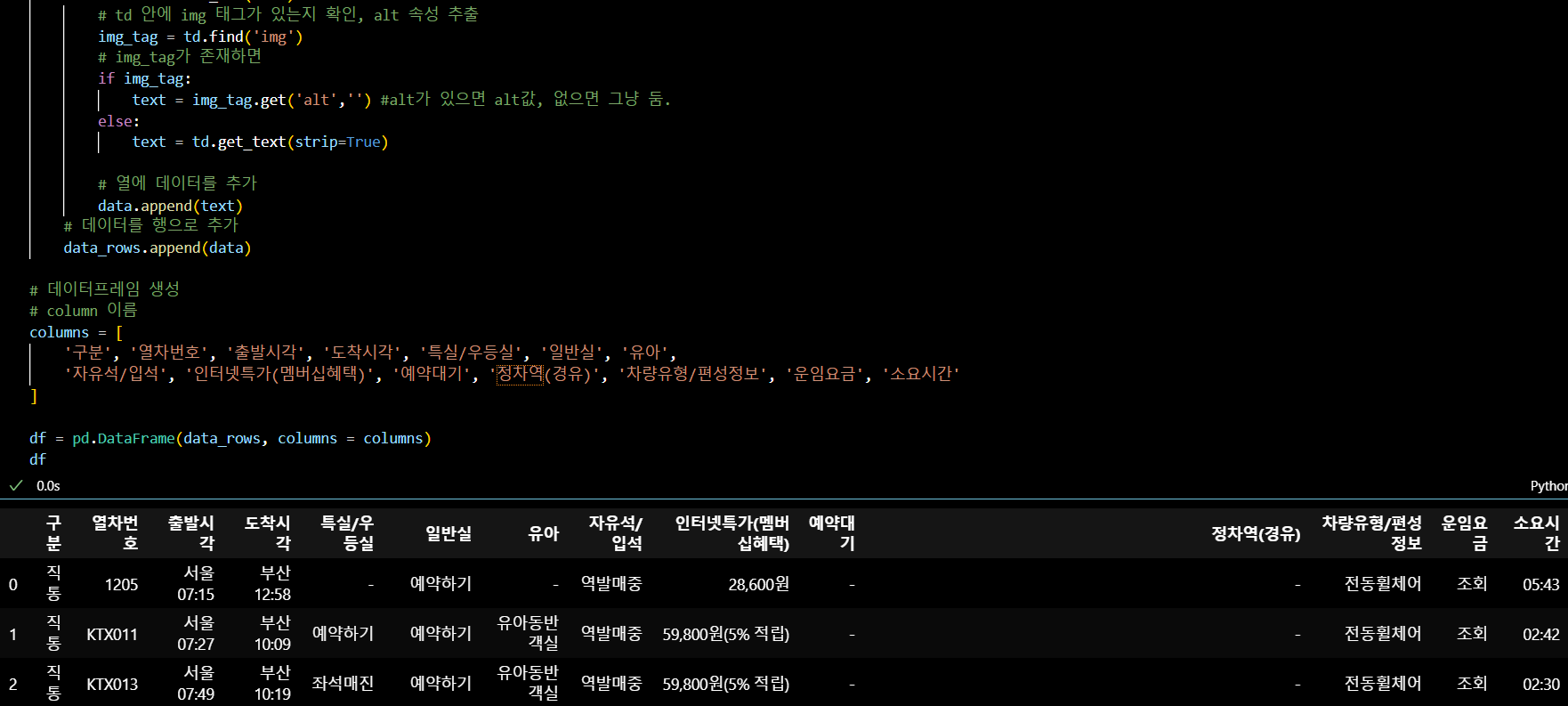
따라서 td만 찾는 것이 아니라 td 하위의 img 태그를 찾아 img가 있으면 alt에 적힌 텍스트를, 없으면 그냥 텍스트를 가져오는 경우로 나누어 접근했다. 그 결과, 데이터 수집 1 이미지에서는 공란이었던 칸에도 데이터가 들어왔음을 확인할 수 있다.
텍스트가 추출되지 않거나 태그를 찾지 못한 경우
이 챕터에서는 URL까지 추가하여 데이터를 가져오는 것을 연습하고 XPath를 사용해 페이지네이션을 진행한다. XPath는 태그의 특징적인 부분을 찾아 경로를 가져오는 방법이라고 한다.
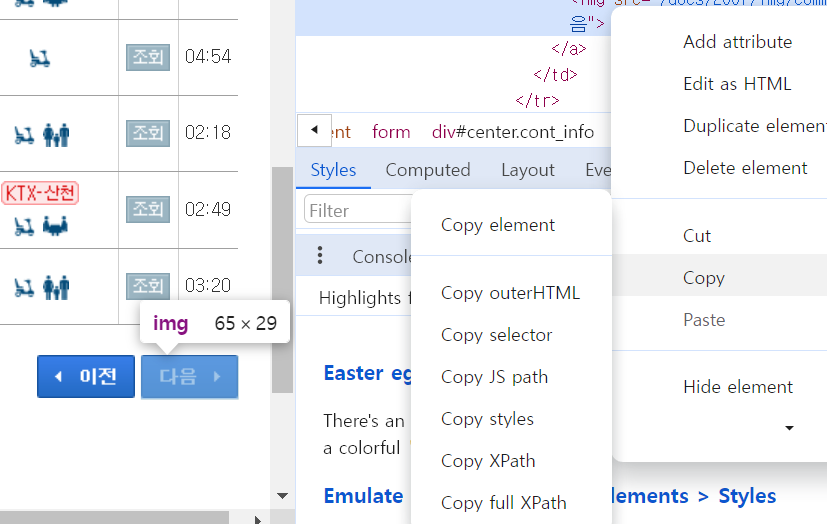
개발자 도구에서 특정 부분을 클릭하고 복사 방법을 지정해서 XPath를 가져올 수 있다.

XPath로 '다음' 버튼을 눌러 다른 페이지의 데이터를 가져오는 코드의 일부다. XPath를 사용하기 위해서는 By라는 라이브러리를 가져오고, try, except로 예외 처리를 하여 에러를 방지해야 한다. 에러가 발생하는 이유는 '이전', '다음' 2개의 버튼이 있는 페이지와 '다음'만 있는 페이지가 있기 때문이다.

실수 체크
크롤링 시 지나치게 시간이 오래 걸리는 경우가 있다. 본 강의에서는 2분 정도 넘어가니 중간에 멈추고 코드를 수정했다. for문의 들여쓰기를 변경하고 불필요한 코드를 삭제하여 시간을 단축했다. 그랬더니 40초대로 줄었다.

표의 내용에 중복이 있다면, drop_duplicates로 하나만 남길 수 있다. subset은 기준, keep은 어느 데이터를 남길지 선택하는 파라미터다.
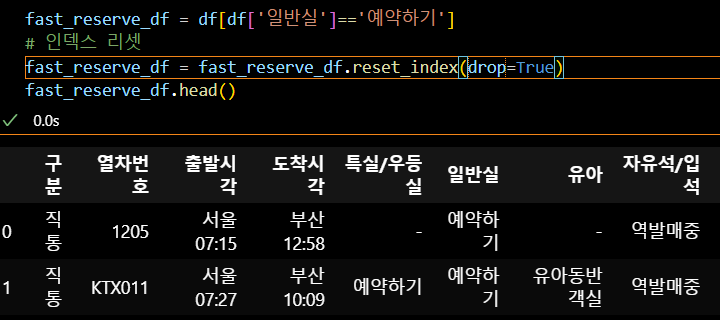
그리고 '예약하기'가 있는 데이터를 찾고 loc로 가장 이른 시간에 출발하는 기차의 URL을 가져와 보다 빠르게 티켓을 예매할 수 있다.
이전에도 몇 번 크롤링을 해본 적이 있으나 XPath로 한 것은 처음이라 신선했다. 다음 메타코드M 강의에서는 리뷰 데이터를 가져오는 프로젝트를 진행할 것이다.
'Python > Web Crawling' 카테고리의 다른 글
| [데이터 수집] 메타코드M '웹 크롤링 기초 강의' #4 (fin) - 관광상품 리뷰 데이터 크롤링 및 분석 프로젝트 (0) | 2024.03.30 |
|---|---|
| [데이터 수집] 메타코드M '웹 크롤링 기초 강의' #2 - 뉴스 크롤링 자동화 프로젝트 (2) | 2024.03.27 |
| [데이터 수집] 메타코드M '웹 크롤링 기초 강의' #1 - 크롤링 필수 이론 (0) | 2024.03.26 |


