
지난 메타코드 강의에서는 크롤링을 하기 위한 기초 이론을 공부했다. 이번 글에서는 크롤링으로 뉴스 기사를 가져오고 이를 자동화하는 프로젝트를 해보고자 한다. 강의는 주피터와 VSCODE를 쓰지만 필자는 Colab으로 코딩을 하고 보다 최신의 데이터를 가져오기 때문에 차이가 있을 수 있다 (강의 24년 2월, 블로그 24년 3월 데이터 활용).
※ 이전글: 2024.03.26 - [Python/Web Crawling] - [데이터 수집] 메타코드M '웹 크롤링 기초 강의' #1 - 크롤링 필수 이론
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr
Index
2강. 뉴스 크롤링 자동화 프로젝트
Beautifulsoup 활용 뉴스 데이터 크롤링
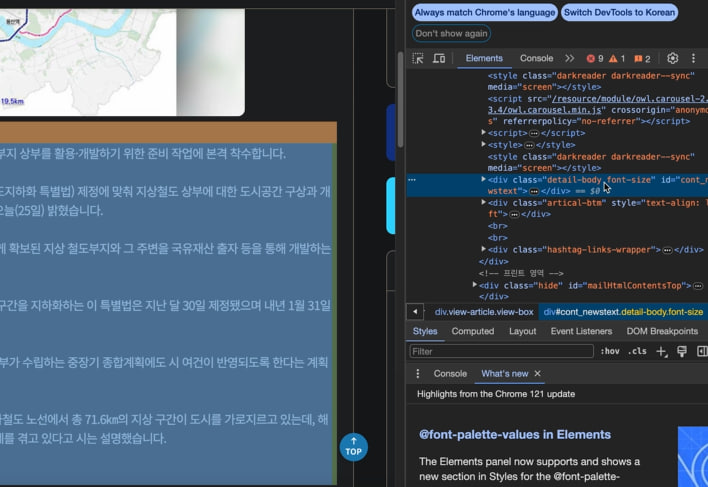
KBS 뉴스 기사를 선택해 F12키를 눌러 구조를 살펴본다. <div>부분에 기사 본문이 담겨 있고, 여기서 <br>은 엔터 (줄바꿈)을 뜻한다.
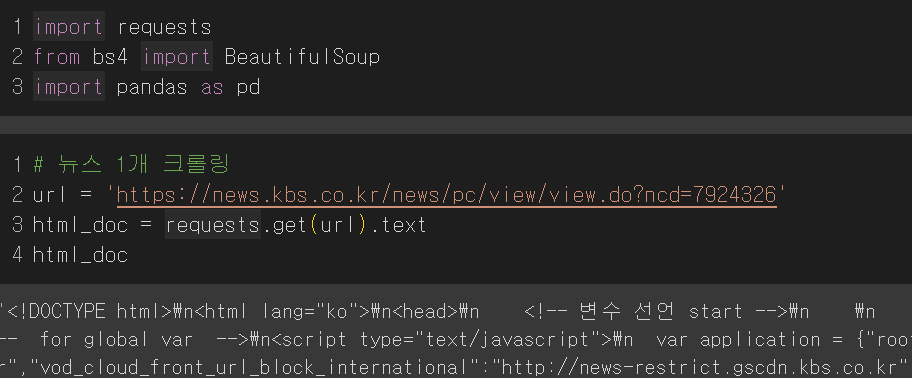
임의의 뉴스 1개를 선정해 데이터를 가져오는 실습을 진행했다. requests를 통해 뉴스 데이터에 접근하고 get으로 해당 URL의 데이터를 text만 가져오도록 코딩했다.

이전 수업에서 다루었던 것처럼 데이터에 원활히 접근하기 위해 beautifulsoup를 써서 파싱한다. class_라는 파라미터로 상세옵션을 줄 수 있는 것은 새로 배웠다.

불러온 뉴스 기사의 데이터를 딕셔너리 형태로 만들고 이를 데이터프레임화했다. 또 CSV 파일로 저장했는데 구글 코랩에서는 화면 좌측의 폴더를 눌러 CSV 파일을 확인하거나 다운로드하는 것이 가능하다.
질문
Q: 'class_'로 파라미터를 사용하는 이유는 무엇인가?
A: 파이썬 내장 키워드인 'class'와의 충돌을 피하기 위해서
2024.04.09 추가
리스트 활용 뉴스 데이터 크롤링

이전 챕터에서 하나의 데이터만 불러왔다면, 이번에는 여러 뉴스 기사의 데이터를 불러오는 것을 다룬다. URL, 제목, 본문이 들어갈 빈 리스트를 만들고 append로 파싱한 텍스트를 추가했다.

위 이미지에서 2개 기사의 데이터가 들어간 것을 알 수 있다. 그리고 반복문으로 이 과정을 단순화하는 것도 가능하다.
url_list = []
title_list = []
body_list= []
urls = ['https://news.kbs.co.kr/news/pc/view/view.do?ncd=7898519',
'https://news.kbs.co.kr/news/pc/view/view.do?ncd=7898517'
]
for url in urls:
html_doc = requests.get(url).text
soup = BeautifulSoup(html_doc, 'html.parser')
title = soup.find('h4', class_='headline-title').text
body = soup.find('div', class_='detail-body font-size').text
url_list.append(url)
title_list.append(title)
body_list.append(body)
data = {'뉴스url':url_list, '제목':title_list, '내용':body_list}
df = pd.DataFrame(data)
df.to_csv('news12_kbs_same.csv', index=False)크롤링이 되지 않는 경우: Javascript 페이지 대응

지금까지는 Colab으로 코딩했으나 이번 챕터부터는 VSCODE로 진행하는 것을 권한다. 매번 라이브러리를 설치하는 것이 귀찮기도 하고 Selenium을 Colab으로 실행하려면 별도의 처리를 해야한다는 얘기가 있기 때문이다. 그리고 실제로 Colab으로 본 강의의 코딩을 진행했더니 에러가 발생했다. 에러를 직접 수정할 정도의 실력자가 아니라면 강의와 동일한 환경으로 수강하는 것이 편할 것이다. 강사님과 동일한 환경 세팅은 다음의 영상을 보고 따라하면 된다. (링크)
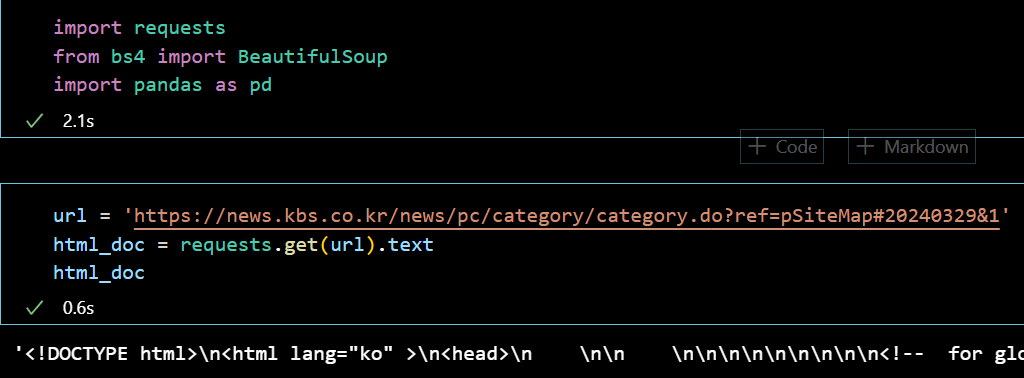
KBS 홈페이지에서 [분야별] - [전체]의 주소를 가져온 다음, 파싱을 진행한다. 그런데 이전과 달리 빈 리스트를 가져오는데 이 원인으로는 다음을 추측해볼 수 있다.
- 크롤링하고자 하는 태그를 잘못 입력.
- Javascript가 사용된 페이지의 데이터의 출력.
첫번째 경우라면 태그를 다시 수정하면 되지만, 후자는 다른 방법으로 크롤링을 진행해야 한다. 대부분의 웹 페이지가 Javascript의 동적 데이터를 불러오기 때문에 Selenium이라는 툴을 쓴다. Selenium은 웹 페이지를 자동으로 제어, 테스트할 수 있는 도구다.
다음으로 Selenium과 Webdriver_manager를 설치한다. Webdriver_manager는 크롤링 시, 크롬 웹드라이버 매니저가 요구되는데 업데이트마다 다시 깔아야 하는 것을 자동으로 처리해주어 편리하다고 한다.
# Selenium으로 웹 드라이버를 실행
service = Service(executable_path=ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# url 전달
url = 'https://news.kbs.co.kr/news/pc/category/category.do?ref=pSiteMap#20240329&1'
driver.get(url)
# 기다려달라는 값을 전달 : 최대 10초 기다리기
wait = WebDriverWait(driver, 10)
# 드라이버 접근 > 페이지 소스 가져오기
html = driver.page_source
# 드라이버 종료
driver.quit()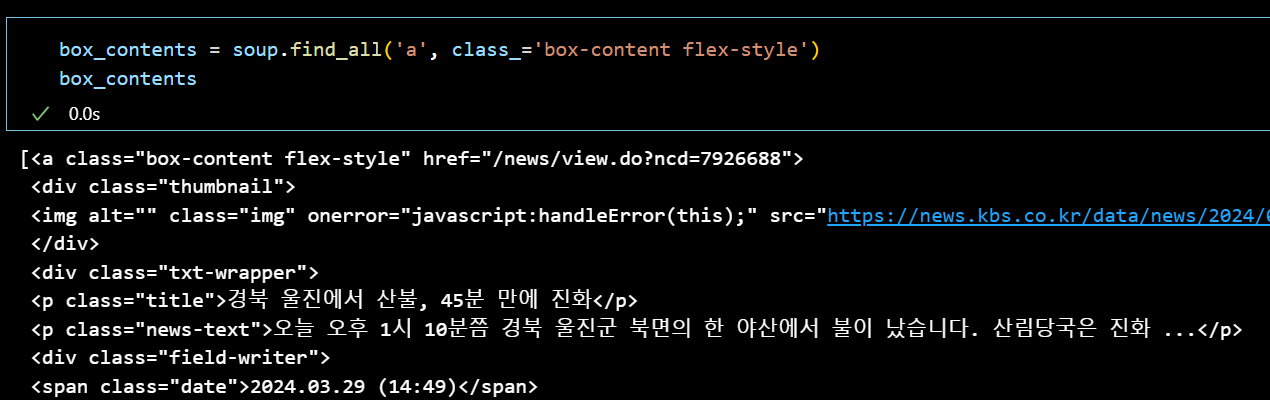
상기 코드를 실행하면, 크롬이 열렸다 닫히며 데이터를 가져온다. PC 환경에 따라 페이지의 로딩 속도가 다르기 때문에 대기 시간을 설정한다. 이 부분은 requests를 대체하는 방법이라 볼 수 있다.
Service를 설정하지 않으면 WebDriver의 경로를 따로 전달해야 한다. executable_path는 원래 Chrome WebDriver가 어딨는지 알려주는 변수라고 한다.
requests와 Beautifulsoup로 빈 리스트를 가져왔지만 이번엔 제대로 웹 페이지의 데이터를 가져왔다.
* 정적 페이지 & 동적 페이지
정적 페이지는 서버로부터 데이터를 요청하면 변하지 않는 형태의 HTML로 작성된 페이지이다. 서버 측에서는 미리 준비가 되어 있어 클라이언트 측에서 별도의 처리없이 바로 브라우저에 띄우게 된다. 크롤링을 위해 Requests와 Beautifulsoup를 쓴다.
한편 동적 페이지는 웹 페이지에서 HTML을 받고, 이를 브라우저가 해석 및 실행하며 Javascript등의 스크립트 언어로 동적 페이지를 만든다. 입력, 클릭, 스크롤 등의 상호작용이 들어간 웹 페이지가 동적 페이지에 해당되고 Selenium으로 크롤링해야 한다.
Selenium, WebDriver 활용 데이터 크롤링
len으로 가져온 데이터의 전체 길이를 확인하고 날짜, URL, 타이틀, 본문을 정리해 CSV로 저장하는 작업을 실시했다.
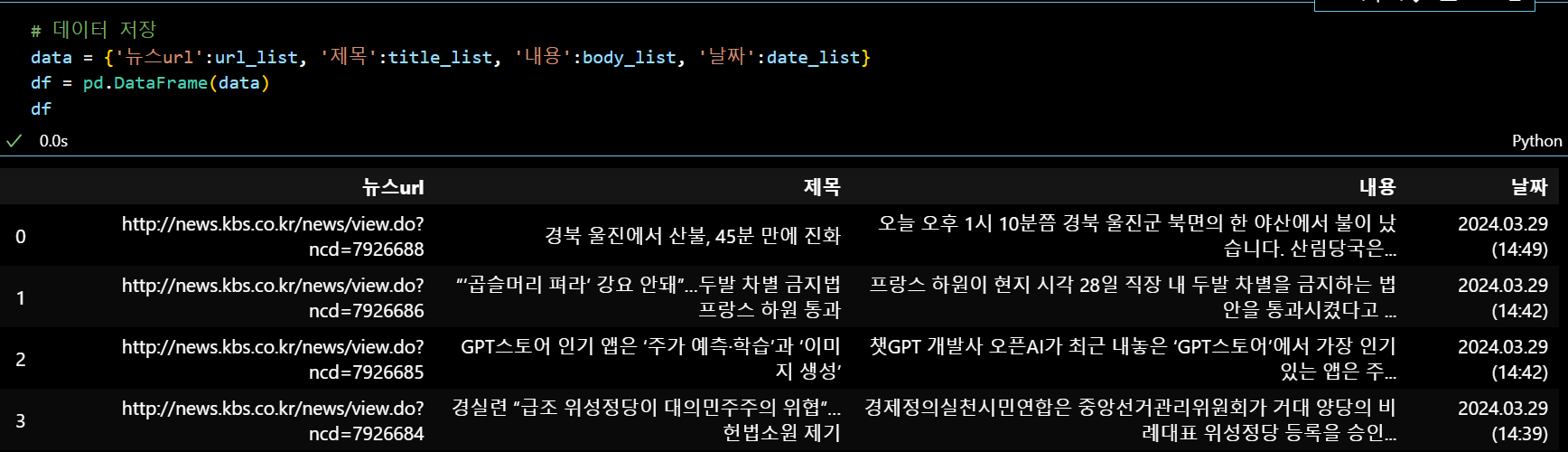
간혹 본문이 없고 이미지만 실린 기사가 있기 때문에 CSV 파일을 열어 확인해볼 필요가 있다.
리스트, 페이지네이션 결합으로 효율성 제고
페이지네이션은 웹 페이지의 특정 페이지를 돌면서 데이터를 가져오는 것을 말한다. 이 강의에서는 f-string과 페이지네이션으로 크롤링을 실시했다. 3월 29일 3시 경의 KBS 뉴스는 24페이지까지 있어서 이를 반영해 변수를 설정했다.

24번 페이지를 열었다 닫으며 데이터를 가져오는 데 3분 가량의 시간이 소요됐다. 해당 일자의 기사가 몇 페이지씩 올려져 있는지 최대 페이지 수를 확인하는 방법을 알아두면 좋을 듯하다.
RSS 활용
RSS (Really Simple Syndication) 는 웹 사이트에서 콘텐츠를 유저에게 쉽고 빠르게 배포하기 위한 표준 포맷이다. RSS를 쓰면 유저가 웹 사이트를 방문하지 않아도 해당 사이트의 업데이트 내역을 확인할 수 있다. RSS는 웹 사이트의 업데이트를 살펴보고자 할 때 사용하고 크롤링은 데이터를 자동으로 수집하고 분석하기 위해 쓴다는 것에서 차이가 있지만, 둘 모두 웹에서 콘텐츠를 가져오는 방법이다.
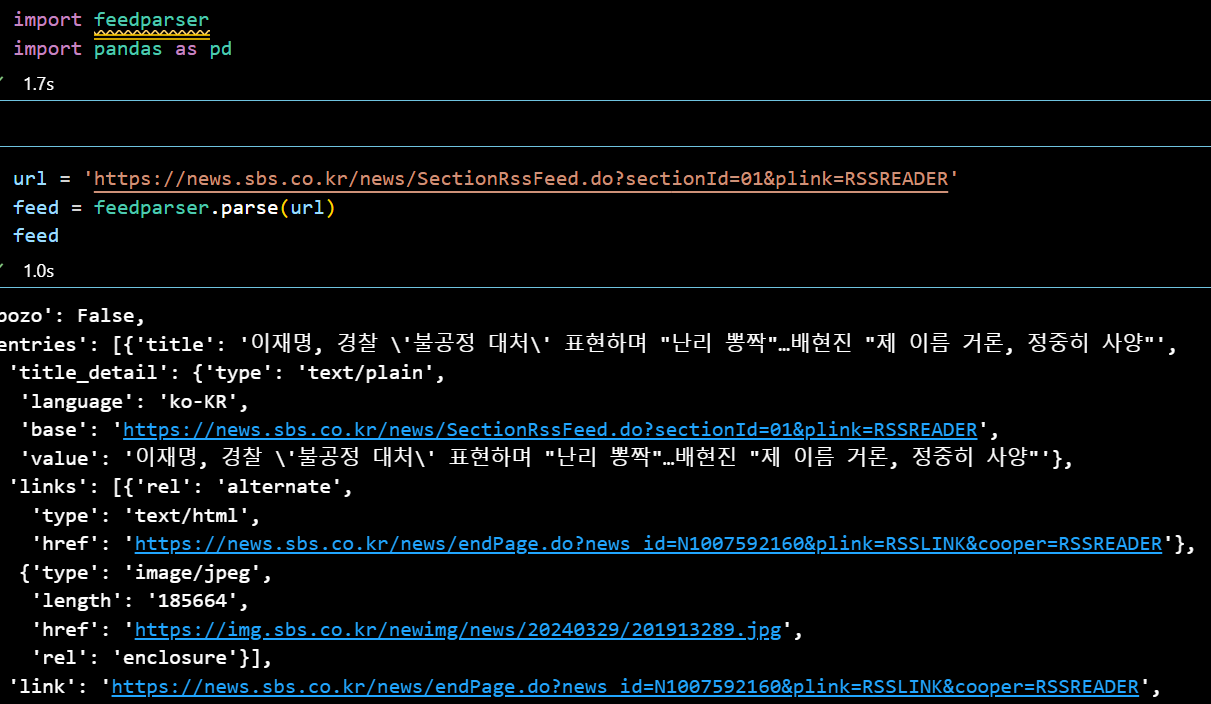
feedparser 설치 후 사이트에서 RSS 데이터를 가져온다. 이번엔 SBS에서 데이터를 가져왔다. HTML과 구조가 다르다는 것에 유의해야 될 것 같다.
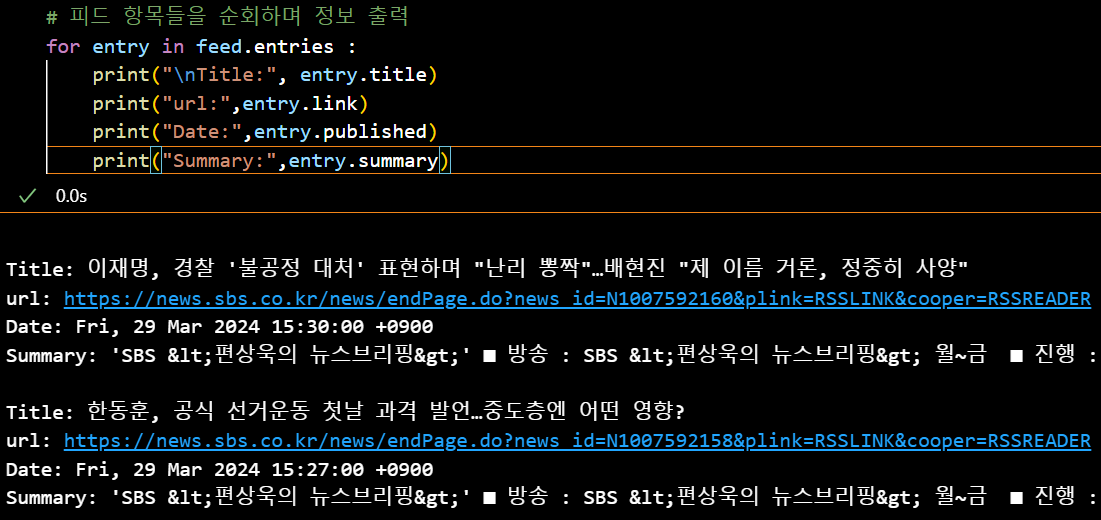
제목, URL, 일자, 요약만 가져온 결과이다. \n으로 출력값을 한 줄 공백을 넣어 가독성을 높였다. 이후, 지금까지와 마찬가지로 빈 리스트를 만들고 이곳에 데이터를 넣는 반복문을 짜서 CSV로 저장하는 작업을 진행했다.
메타코드M '웹 크롤링 기초 강의' - 뉴스 크롤링 자동화 프로젝트는 이것으로 마무리하고자 한다. 영상 화질이 4K까지 지원되기에 선명하게 볼 수 있어 좋았다. 다음 강의에서는 다른 크롤링 프로젝트를 실습할 것이다.
- 24.04.09 질문 추가
'Python > Web Crawling' 카테고리의 다른 글
| [데이터 수집] 메타코드M '웹 크롤링 기초 강의' #4 (fin) - 관광상품 리뷰 데이터 크롤링 및 분석 프로젝트 (0) | 2024.03.30 |
|---|---|
| [데이터 수집] 메타코드M '웹 크롤링 기초 강의' #3 - 기차표 티켓팅 프로젝트 (0) | 2024.03.29 |
| [데이터 수집] 메타코드M '웹 크롤링 기초 강의' #1 - 크롤링 필수 이론 (0) | 2024.03.26 |


