데이터가 쌓이고 이를 처리하는 기술이 발달함에 따라 데이터를 학습해 결과물을 생성하는 인공지능도 발전해왔다. 이 추세라면 머지 않아 인공지능이 인간의 일자리를 대체할 것이라는 예측은 누구나 했으나 창작의 영역만큼은 예외라 생각했었다. 하지만 글을 짓고, 그림을 그리고, 노래를 만드는 등 인간 고유의 감성이 중요한 것으로 여겨져 온 분야에서 인공지능이 두각을 드러내고 있다. 과연 2023년 2월 현재의 인공지능은 어느 수준의 그림을 그릴 수 있을까 직접 체험해봤다.

Index
인공지능 그림의 발달사
이 챕터는 디시인사이드에서 잘 정리된 글 (링크)이 있어 참고하였다. 인공지능이 그림을 그리는 원리까지 파고 들면 GAN 등의 쉽지 않은 개념을 다루어야 하니 스킵하겠다. 이 글의 독자들이 AI 그림을 처음 접한 것은 아마 특정 표현을 입력하면 거기에 맞게 그림을 그려주는 프로그램이 아닐까 싶다. 필자 역시 그것에 강렬한 인상을 받았고 직접 OpenAI에서 DALL-E의 사용을 요청하기도 했다.
그러다 어느날부터인가 디스코드에서 그림을 그리는 인공지능이 주목을 받았다. Midjourney라는 이름이고, 여러 스트리머들도 직접 체험기를 방송했던 것으로 기억한다. 하지만 이 모델은 굉장히 폐쇄적이라 매력이 떨어졌는데 이 와중에 뮌헨 대학교에서 Stability AI 등의 지원을 받 Stable Diffusion이라는 개선된 알고리즘을 만들었고 오픈 소스로 공개하였다. 이를 기반으로 유료 모델인 NovelAI가 나왔으나 바로 소스까지 누군가에 의해 노출되었고, 그 데이터를 토대로 WebUI에서 무료로 이미지를 생성할 수 있게 되면서 근래 많이 회자되고 있다.
Stable Diffusion WebUI 설치 및 실행
이제 배경을 살펴봤으니 직접 이미지를 만들어보자. 이 챕터는 유튜브에 있는 조코딩의 영상을 참고하였다 (링크). 순서는 다음과 같다. 참고로 필자는 구글 Colab을 활용한 방법 (TheLastBen)으로 진행하였다.
- Stable Diffusion WebUI 깃허브 (링크) 이동 후 'Installation and Running' 아래의 'List of Online Services' 클릭.
- 원하는 방식의 colab 파일 실행.
- colab에서 코드를 실행하고, 'Model Download/Load'에서 옵션 지정. 필자는 기본 모델과 다운로드 받은 모델의 경로를 입력하여 테스트함.
- Start Stable-Diffusion의 코드를 돌리고 URL 접속.
- 해당 페이지에서 이미지 생성. 아래 용어 설명 참고.
- Prompt : 생성할 이미지의 키워드 입력
- Negative Prompt : 이미지에서 반영하지 않을 키워드 입력
- Batch Count : 이미지 생성 작업을 Batch라고 함. 따라서 batch count는 이미지를 만들 횟수 의미.
- Batch Size : 하나의 Batch에서 동시작업할 수량.
- Sampling Step : 인공지능이 노이즈가 있는 이미지를 복구할 때, 거쳐야 하는 단계 수. 많은 단계를 거칠수록 깔끔한 이미지가 되지만 시간이 많이 소요됨.
- CFG Scale : 프롬프트 태그의 값을 얼마나 충실히 구현할 지에 대한 값.
- Sampling Step과 CFG Scale에 대한 가정 (링크)
이미지 생성
AbyssOrangeMix2_hard
애니메이션과 실사를 적절하게 섞은 것으로 알려진 모델이다. 해당 모델에게 매력적인 남자 (gorgeous man)를 그려달라고 지시해봤다.
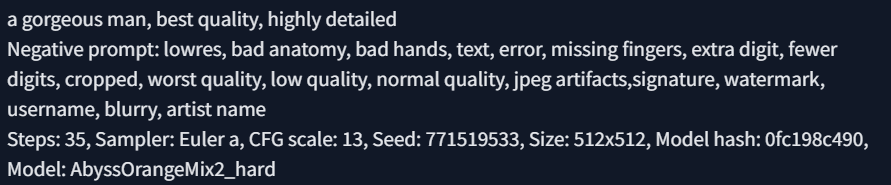



손가락 처리가 이상한 그림도 있지만, 이런 느낌의 이미지를 8장 생성하였다. 해당 모델에게 있어 매력적인 남자란 하얀 피부에 장발, 그리고 수트를 입은 유형으로 인식되는 듯하다. 다음으로는 미녀 (beauty)를 요청하였다.
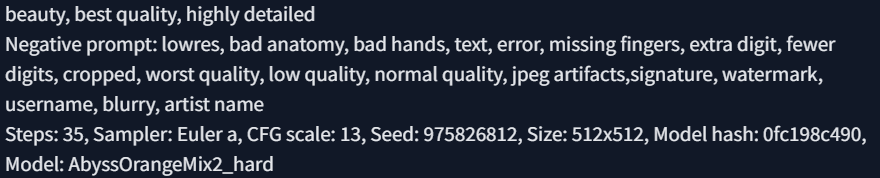


글래머러스한 몸매에 수줍은 듯한 표정을 지은 이미지를 그려냈다. 나머지 사진은 차마 정지받을 것 같아 올릴 수 없었다.
pastelMixStylizedAnime
애니 분위기가 나도록 파스텔톤의 그림을 그려주는 모델이다. 근데 왜 마스터피스로 하면 죄다 여자가 나오는지...?



두번째 그림은 지옥의 무서운 왕으로 정해봤다. 근데 뭐 얼굴이 다 반반해서 지옥에 떨어진 것들이 공포감을 느끼려나 모르겠다.



Kenshi_01
이 모델로는 배경과 캐릭터를 그려달라고 지시했다. 필자가 살고 있는 지역의 호수를 연상해서 몇 가지 키워드를 입력했다. 그리고 한국의 야경, 한국인 게이머도 부탁하였다. 키워드를 입력하여도 학습된 이미지가 없다면 완벽하게 반영하지는 못하는 것으로 보인다.






이처럼 단시간에 꽤나 퀄리티있는 이미지를 생성할 수 있다는 점에 놀라기도 했지만 아직 세부 표현에서는 보완해야될 부분이 눈에 띄었다. 그래도 급한 상황이거나 내용이 단순하다면 충분히 쓸 만하다는 생각이 든다. 기업에서도 기존의 아트 작품을 학습시켜두면 비슷한 컨셉의 작품을 뽑아가며 테스트할 수 있을 것으로 예상된다. 한편 인공지능이 새로운 이미지를 만들어내기까지 타인의 저작물을 허락없이 무작위로 학습한다는 것과 성인물까지 영역을 넓히고 있다는 점에서 시급히 이와 관련된 룰이 제정될 필요가 있겠다는 생각도 들었다. 행정과 사법은 대체로 산업의 변화보다 늦기 때문에 그 공백을 최소화하는 것이 관건이 될 것이다.



